实战:分布式 selenium 爬虫,突破 craigslist 反反爬虫机制
爬虫和反爬虫的军备竞赛
爬虫是很传统的应用。 通过爬虫,我们可以从互联网服务中自动化大规模收割我们需要的数据和信息。 服务供应方,也就是被爬虫抓取数据的网站,出于保护数据版权,降低服务器负载等目的,设置各种各样的反爬机制。 工程技术领域的攻防问题大多是道高一尺魔高一丈的军备竞赛。 面对防御方的各种防御机制,可以通过对具体问题的针对性分析,逐一破解。
如同所有的工程开发一样,这一过程中最昂贵的成本就是摸着石头过河的技术探索成本。 本文就是对 Craigslist 这一具体案例的技术探索过程的记录,希望可以帮助后人降低学习成本,迅速掌握爬虫技术。
爬虫的法律相关
Disclaimer:本节内容不构成法律建议!!!
笔者对我国法律实践了解较少。 美国的爬虫相关案例中,较近的有 hiQ 诉 LinkedIn 案1,联邦第九巡回上诉法院于2022年底裁定,“‘未经授权’的概念不适用于公共网站”,因此 爬取公开数据 的行为并不违反美国《计算机欺诈和滥用法案》(CFAA, Computer Fraud and Abuse Act)23。
第九巡回法院在裁决中指出,
公共网站的一大基本特征,就是其中公开可见的部分不受访问限制;换言之,这些部分将对任何拥有网络浏览器的访问者开放。
也就是说,如果将这些托管公开页面的计算机视为房屋,那么公共网站设备在部署之初就没有设置任何“前门”,自然不存在提高或降低访问门槛一说。因此,Van Buren 案强化了我们的裁定,即 “未经授权”概念确实不适用于公共网站。
作为判例法国家,在联邦最高法院接受本案上诉并重审之前,在美国法律管辖范围内,并无判例支撑 爬取公开数据 的行为违法。
Disclaimer:本节内容不构成法律建议!!!
实际问题: Craigslist 网站的反爬虫机制
Craigslist (下称 CL )是北美应用最广泛的同城分类信息平台之一,自然深受爬虫之害,无数人通过爬取 CL 的数据,构建 app 原型。 针对于此, CL 设置了若干反爬虫机制,大体可以概括成以下两类:
- 用户信息识别:这包括很多种机制,比如
User-agent, cookie ,访问者 IP 等:- 访问者 IP 的请求频率: CL 服务器会识别访问者的 IP 地址,当某一 IP 地址访问频率过高,明显高于人类操作可能性时,这一 IP 地址将被屏蔽。
- 屏蔽 IP 段:可能是由于 CL 并不向中国大陆提供服务, CL 站方屏蔽了一切来自中国大陆地区的访问请求。
User-agent等访问头(request header):和其他根据访问头识别访问者身份的机制一样,可以通过提供若干个User-agent预备来解决。- cookie :初次 http 访问请求一般是无状态的。服务器为了识别身份,在初次访问之后,会返回给浏览器一段数据,即 cookie ,方便用户下次使用。
- 重复大量使用同一 cookie 自然会引起服务器屏蔽这一 cookie 的访问。
- 可以使用 selenium 模拟浏览器行为,每次访问重新生成 cookie ,以破解其用户识别机制
- 访问者 IP 的请求频率: CL 服务器会识别访问者的 IP 地址,当某一 IP 地址访问频率过高,明显高于人类操作可能性时,这一 IP 地址将被屏蔽。
- 动态渲染:
- 现代 web 前端网页一般不会在初次加载时载入所有信息,而是使用动态载入,异步获取数据。比如 AJAX ,网页根据用户行为,实时访问后端,在得到回复后即时渲染。
- 我们无法使用诸如
python-requests一类访问静态网页的库一次性抓取动态网页中的所有信息,因此必须使用selenium一类库模拟浏览器的行为,完整渲染整个网页以抓取信息。
分析结论:需要使用哪些反反爬虫手段,破解 Craigslist 的反爬虫防御措施?
根据上文的分析,可以简单归纳出三种针对性攻击措施,以破解 Craigslist 的防御措施。
- 反侦察措施:使用高匿代理服务器池子,掩盖自身 IP 地址,避免被服务器识别。
- 同理,对
User-agent等访问头,也应做好相应的反侦察措施。 - 我们可以选择免费的高匿代理,也可以选择收费的,为了缩短开发周期,尽快完成原型,我们暂时选择收费高匿代理。
- 收费高匿代理是按照流量计费的,这意味着必须关闭图片接收,尽可能缓存不同网页的重复内容。
- 同理,对
- 动态渲染:我们使用
selenium模拟浏览器渲染网页,以实时生成 cookie ,模拟浏览器的 AJAX 行为。 - 分布式爬虫:由于
selenium对爬虫服务器的资源消耗较大,我们使用分布式系统设计:- 使用消息队列分发任务,由工作者接受任务,使用
selenium和相应的浏览器驱动程序进行爬取,比较流行的有 firefox 系和 chrome 系
- 使用消息队列分发任务,由工作者接受任务,使用
扩展阅读:更多更复杂的反爬虫机制
反爬虫和反反爬虫的军备竞赛是永无止境的,用一张网图表示4:
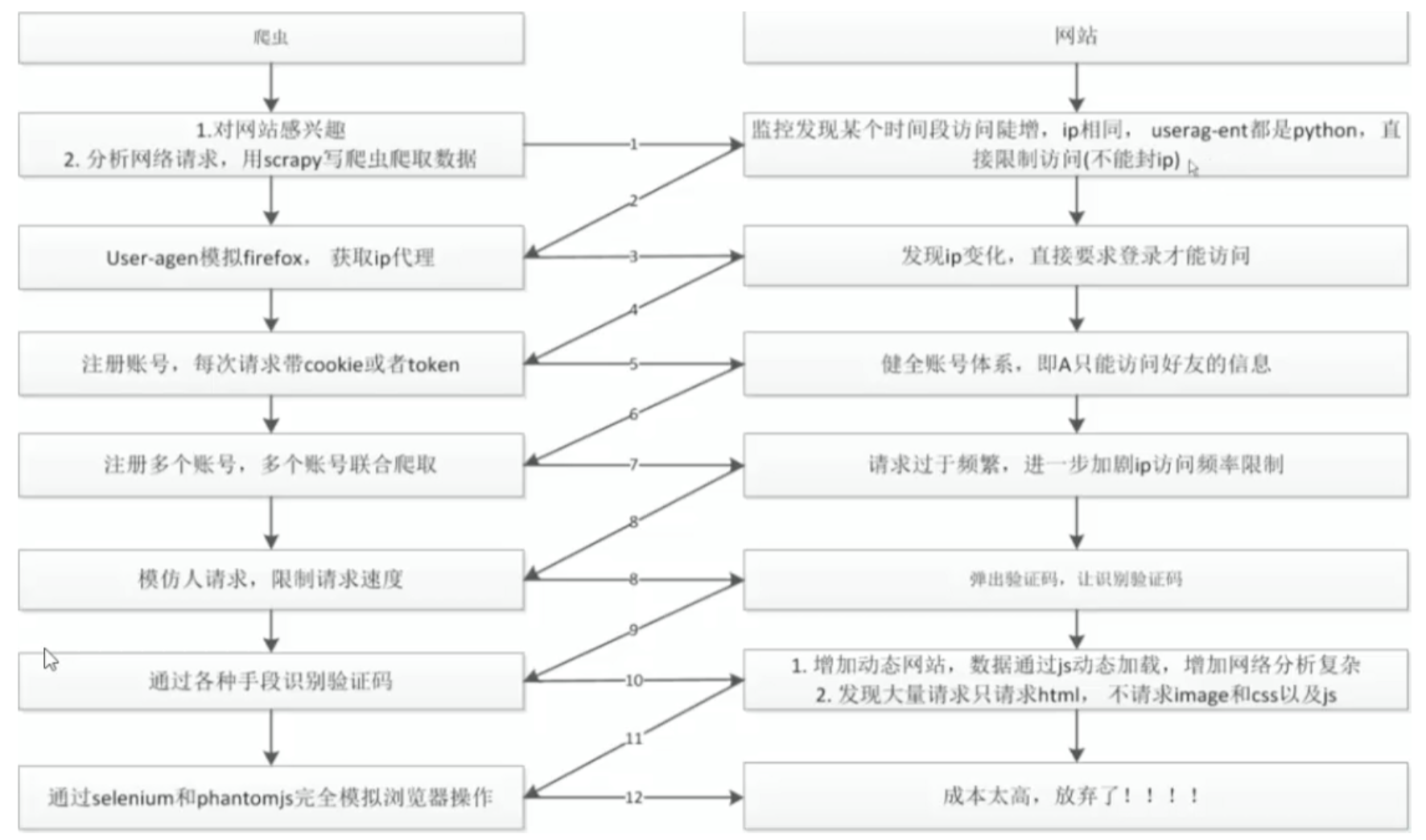
十分幸运的是, Craigslist 并未设置更为复杂的反爬虫机制:
- 数据只允许登录后访问:
- 这个是比较麻烦的,也是我国企业的主流选项。
- 验证码机制:
- 在计算机视觉技术大为发展的今天,解决这一问题并不难。
- 数据加密机制:
- 有很多种手段,比如字体模糊,如下图所示,并不以文本方式渲染全文,而是随机使用与原文本相似的图片替换掉一些文本,以中断我们对文本的抓取。
- 与验证码类似,也可以使用 OCR 技术破解已经被 selenium 渲染的网页来抓取所需的信息。
- 有很多种手段,比如字体模糊,如下图所示,并不以文本方式渲染全文,而是随机使用与原文本相似的图片替换掉一些文本,以中断我们对文本的抓取。

开发的第一步:技术选型、开发流程、系统设计
孙子兵法中说过,
夫未战而庙算胜者,得算多也;未战而庙算不胜者,得算少也。多算胜,少算不胜,而况于无算乎!吾以此观之,胜负见矣。
我们把一个项目的开发比喻为一场战役的话,了解作战的环境(天时、地利、人和),分析敌情,提出作战方案和作战计划,就是开发中的庙算。 庙算较多,可以磨刀不误砍柴工,节约后续的开发周期和成本。 “多算胜,少算不胜”的道理,也同样适用于市场的竞争。
庙算的目的是什么? 不同的作战方案必然会有不同的效果。通过开发前的技术讨论,选择一个较好的作战方案,可以缩短开发周期,节约开发成本,夺取市场竞争优势。
在庙算之中,我们需要:
- 分析己方的人和(团队组成和人员结构、技术栈)。
- 分析假想敌(项目需求,在本文中是敌方的反爬虫机制)。
- 提出作战方案(技术选型、分解项目需求到开发流程和系统设计)
- 根据作战方案制定作战计划(安排和推进开发流程到团队日程表上,可以使用甘特图( Gantt chart )5推进项目)
技术选型的标准和过程
根据个人经验,笔者个人在进行技术选型的时候,一般会有如下标准(排名不分先后):
- 这一技术我会不会?如果我不会的话,学习成本有多高?(人和)
- 很多情况下开发周期都是最重要的课题,不论对于处在任何阶段的企业,高速抢占市场都是至关重要的。
- 这一技术在市场上的流行度?(人和)
- 雇佣一个掌握这一技术的工程师,大概的难易度和成本,决定了后续维护和开发的成本。
- 这一技术的后续伸缩难度和成本?
- 互联网的魅力之一就是可以以较低成本进行大规模伸缩,所以有必要在系统设计之初就考虑到后续的伸缩需求。
- 这一技术的开发、调试和维护成本?
- 开发成本,或者说工程师的工时工资,一般是开发过程的最大成本。
- 稳定性和可维护性是非常重要的。
- 通用技术 vs 专用技术?
- 专用技术(如 Scrapy )往往有较丰富的功能,更加贴合于具体的应用场景(爬虫)。
- 通用技术(如 Celery )则是更高层次的抽象(任务队列),适用于更多的应用场景,但具体到特定的应用场景,则未必有专用技术强大广泛的功能适配。
- 很多情况下,项目早就采用了某种通用技术,此时有必要讨论是否有必要引入新的专用技术:开发成本是多少?我们真的有必要引入那些功能吗?这些都是权衡与取舍。我们总是说“重复发明轮子”,事实上重复学习轮子也是要规避的。
现实工程中需要考虑的问题往往都是权衡与取舍,技术本身的可行性一般都是没什么问题的,需要考虑的更多都是开发成本、开发周期、维护成本等因素。
即使是对于创业企业而言,技术选型的讨论过程也是值得留档记录的。作为项目文档的一部分,方便新人工程师接手项目。
我们的技术选型
- 开发语言: Python
- 选型原因:开发快,懂的人多
- 爬虫框架: Selenium
- 选型原因:上文叙述过,必须使用 Selenium 模拟浏览器行为,动态渲染网页
- 浏览器驱动程序: Chrome
- 这个其实经历了反复改换,在 Firefox 和 Chrome 之间斟酌不定,最后选择 Chrome 的原因是我在 StackOverflow 上找到了如何使用 Chrome 保存浏览器缓存
- 对于 Craigslist 上的大部分网页,我们下载的内容都是模板 + 数据,为了节约流量,我们只希望下载数据,不希望重复下载模板
- 这个其实经历了反复改换,在 Firefox 和 Chrome 之间斟酌不定,最后选择 Chrome 的原因是我在 StackOverflow 上找到了如何使用 Chrome 保存浏览器缓存
- 包管理: Conda
- 其他项目会用,一般来说其实用 pip 就好
- 由于我们使用 conda ,可以在 iPython Notebook 里进行原型开发,缩短开发周期,也算一个优势
- 消息队列: Celery + RabbitMQ
- Python 的任务队列库,进行分布式任务分配
- 一般需要配合 RabbitMQ 或 Redis 等消息队列服务作为 Celery 的 broker ,这里选用 RabbitMQ
- 不选择 Scrapy 的原因:相比起 Scrapy 是高度特化的爬虫框架, Celery 是更基础的抽象,可以广泛应用到其他的业务开发中
- 集群管理: Kubernetes + Docker
- 选型原因:负责集群管理和容器的自动化运维:可以以非常低的成本扩张,大幅度降低运维成本,适配其他服务的开发也十分简易
- 与本文不相关的技术选型:
- 数据库及驱动程序: PostgreSQL + SqlAlchemy
- 后端框架: FastAPI
开发探索步骤
上边讨论了这么多,终于产品经理要出场了,提出并分析技术需求( PRD, Project Requirements Document )。
需求:我们想要获得 Craigslist 上旧金山湾区所有的租房房源信息。
探索(即开发任务):
- 使用代理:学会使用高匿代理、 Selenium 及其 webdriver 刮取网页……
- 列表抓取:
- 抓取第一个网页:尝试抓取 Craigslist 的 list 部分6,即房源列表中所有房源的链接。
- 抓取后续网页:仅仅有一页房源列表肯定是不够的,需要探索如何用可靠的手段抓取房源列表的下一页。
- 更新任务队列:当我们得到列表中的所有这些链接之后,我们把这些链接推送到 Celery 队列中,作为下一步爬虫工人(
celery worker)们的任务(task)。 - 定时任务:为了确保房源数据库与 Craigslist 尽可能同步,我们需要周期性运行 列表抓取,抓取新的房源。
- 为了避免重复抓取,每次运行 列表抓取 的时候,我们从新到旧抓取房源,当我们抓取到的最旧一条房源,早于数据库中尚存的最新一条房源的时候,我们中止 列表抓取 这一过程。
- 这一过程可以做成 Kubernetes 中的定时任务 Crontab ,简化运维
- 针对 Craigslist 特化的需求:对于某一个选定的区域, Craigslist 仅仅提供前 10000 条记录(或最近一个月的记录),但旧金山湾区是个很大的区域,前 10000 条记录仅仅包括了三天的更新量。
- 对每一个选定的大区域(旧金山湾区),Craigslist 另外提供一些子区域给我们搜索,旧金山湾区包括城里(即旧金山市)、东湾、南湾、北湾、半岛、 Santa Cruz 等地区,通过追踪这些地区的更新,可以获得一个较久的数据储备。
- 房源抓取:
- 抓取第一个网页:需要剖析 Craigslist 网页内容,输入数据库
- 数据库设计:选择哪些网页内容进行剖析和储存?选择什么样的数据类型储存这些内容?
- 处理重复项:如何判定两个房源是重复的?这可以节约后续 定时淘汰 步骤耗费的流量。
- 抓取后续网页:使用 K8s 的 deployment 部署若干个 Celery worker 进行抓取
- Celery worker 的容器化和集群部署
- 如何配置 Celery worker 的容器,使其共享浏览器缓存,节约流量
- 在后续运行中,我们可能还会面对如何处理 Celery worker 的优雅失败
- 定时淘汰
- 数据库中的房源可能会随着时间流逝而失效,我们需要定期扫描数据库的内容,访问其链接,删除已经失效的内容
- 这同样也是一个定时任务 Crontab
我们需要评定开发任务是否阻碍其他任务,其先后顺序和优先级,估算其消耗时长,进而形成 ticket ,即工单。
把工单排列进入甘特图( Gantt Chart ),管理项目进度。
简单的系统设计,及后续开发中需要注意的原则
Docker 容器化和 Kubernetes 集群管理的使用,大幅度简化了系统设计的思维负担。 我们已经在上述的任务分解中简述了这个简单系统的设计,包含
- K8s 集群(在规模较小时,我们可以直接使用 Minikube )
- 一个消息队列( Celery + RabbitMQ )
- 一个容器部署( K8s deployment ),即 Celery worker
- 两个定时任务( K8s crontab )
- 一个数据库( PostgreSQL )
我们剽窃一张前人撰写的 Celery 爬虫架构图7,给予一个较为直观的理解:
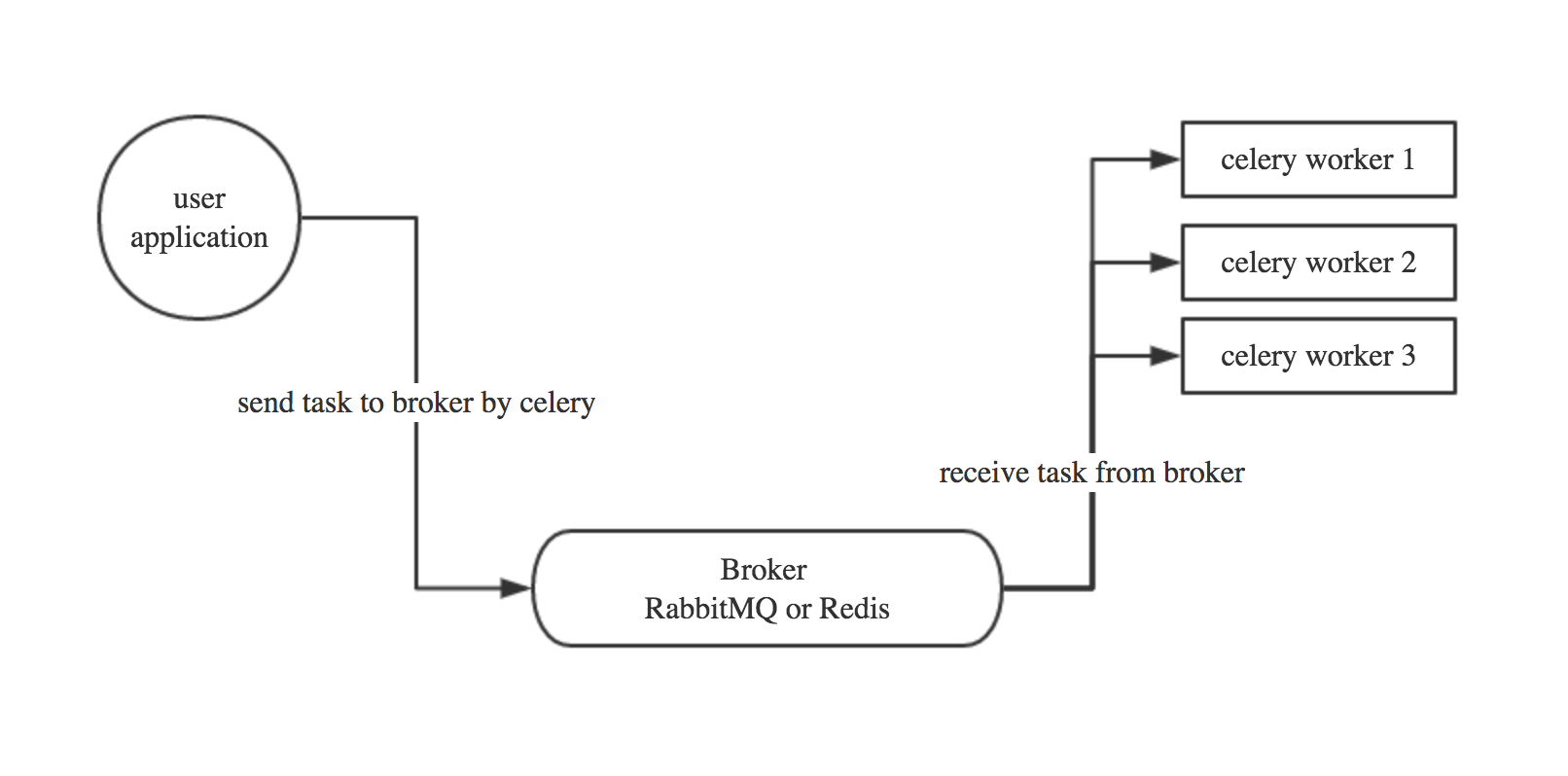
我们根据云原生应用开发的最佳实践,遵循 12 因素应用( 12 Factor Application )8的原则进行开发,以节约后续的维护成本,减少潜在的bug,提高团队的开发体验。 其中较重要的开发原则,比如:
- 在环境中存储配置
- 以无状态进程运行应用
- 快速启动和优雅终止
等。
小结
经过一定的庙算,分析敌情,分析人和,跟踪技术潮流,追随系统设计的最佳实践,提出作战方案,我们可以缩短开发周期,大幅度简化开发流程,以很小的团队完成过去非常困难的工作。 对于创业企业而言,迅速完成原型,就是站稳脚跟的第一步。
但仅仅有第一步是不充分的,通过周密考虑的系统设计和恰到好处的文档,我们可以构建非常健壮的应用程序,节约后续的维护成本,有效应对未来潜在的规模扩张和功能扩展需求,良好应对技术团队的新旧交替,站稳企业生命周期中的每一步。
(回顾本文,我发现我一行代码都没写。 如果本文有下篇,我一定写。)