实战:使用 ElasticSearch 8.13 实现混合搜索(4):使用开源模型,导入真实世界数据
从本文开始我们终于要开始使用 Python 了,数据量实在超越了 Kibana 控制台能处理的规模。 文末会附带 Jupyter Notebook 示例代码,以保证实验的可复现性。
使用开源模型
Cohere 不是免费的,如果把我们的 50 万条数据都丢给 Cohere embedding 算法处理的话,恐怕要产生一笔我们并不想要的信用卡债。
这一步骤事实上已经在 ElasticSearch 官网博客提供的指南 及其示例代码 Jupyter Notebook 中提及。
测试中发现的易出 bug 点在于 eland[pytorch] 库需要 Python 3.10 才能较为顺利的安装。
这里还有一个问题,我们部署本地开源模型的话,需要使用 GPU 加速的云服务,这笔信用卡债似乎很难躲开。 但如果我们的数据规模扩张到难以控制的程度,这笔实践经验就会显得十分宝贵。 我们使用 AWS 最便宜的 g4dn.xlarge 实例运行我们的 PyTorch 服务。 虽然他提供的 nVidia T4 GPU 已经是五年前发布的,但是 T4 GPU 似乎为半精度浮点计算( FP16 )做了特殊的优化,其半精度浮点计算能力高达 65.13 TFLOPS ,十分符合我们的需求。
当然,云服务价格比 r7gd.large 贵了四倍。
而且需要从 AWS 申请限额,可能要等一天才能完成。
我们先在本机上玩,玩透了大概 AWS 也批准了我们的限额请求了。
笔者笔电的 RTX 2070 Max-Q 在大概 4 秒钟之内完成了 Cohere embedding 需要一分钟, CPU 十分钟不一定跑的完的数据,赢麻了。
另外还有一个容易卡住的点,可以参考这一节。
更新: AWS 拒绝了我们提高服务限额的申请。 但工程领域总有绕过的手段,既然我们并不追求数据的实时更新,我们可以先在我们的笔电上完成数据的索引,再通过 elasticsearch-dump 上传到云服务上,这不就赢麻了嘛。
使用 Celery / RabbitMQ 管理大规模数据操作
笔者简单尝试了一下使用 Python 和 ElasticSearch 自带的 bulk 工具导入 50 万条评论数据,效果不佳,事实上仅仅导入了 10 万条。
输入 Best pasta in New York 执行搜索,搜索结果的确令人满意
ID: 32390
Doc Title: review_720045084
Restaurant Name: Tony_s_Di_Napoli_Midtown
Title Review: Fantastic food!
Passage Text:
The best pasta in New York! Great dessert and friendly staff. A bit noisy on a Sunday evening but a really nice evening close to Times square.
Score: 0.9367155
---
ID: 52686
Doc Title: review_651849097
Restaurant Name: Carmine_s_Italian_Restaurant_Times_Square
Title Review: Wonderful
Passage Text:
The best pasta in New York. The only problem is the size of the plates. They must do smaller plates. For one person for example.
Score: 0.90883017
---
ID: 73133
Doc Title: review_628690226
Restaurant Name: Il_Gattopardo
Title Review: Excellence
Passage Text:
Perhaps the best pasta in NY. They can deliver pasta al dente, as they have done that for us in the past.
Score: 0.89915013
---
ID: 1460
Doc Title: review_609031069
Restaurant Name: San_Carlo_Osteria_Piemonte
Title Review: Good if you are not italian
Passage Text:
Nice food in New York if you are not Italian but if you know how Italian food really is you can cook better at your home.Pasta not good
Score: 0.88570404
---
ID: 149
Doc Title: review_695311754
Restaurant Name: San_Carlo_Osteria_Piemonte
Title Review: Outstanding food, great service and atmosphere
Passage Text:
I'm a huge fan of picolla cucina on Spring St and I still think they have the best pastas in New York. It's my favorite in NYC, but a block away is San Carlo which may bemy second favorite. It is slightly different in terms of the menu, with less focus on pasta. It also has a slightly larger footprint with a small intimate bar, and has a very good wine and cocktail list.
Score: 0.8833201
---
ID: 70098
Doc Title: review_417272677
Restaurant Name: Forlini_s_Restaurant
Title Review: Buenísimo!!!
Passage Text:
Best pasta and minestrone soup ever, we been looking around in little Italy New york for a good Italian restaurant, I consult trip advisor. Found the place and was a delightful surprise. Jack where our hostess very kind and funny man. Definitely we are going to come back soon during our trip here in NY.
Score: 0.8831816
---
ID: 87324
Doc Title: review_241290115
Restaurant Name: Carmine_s_Italian_Restaurant_Times_Square
Title Review: Real Italian food
Passage Text:
Best classic Italian food in NYC.
Score: 0.8803612
---
ID: 21092
Doc Title: review_629514788
Restaurant Name: IL_Melograno
Title Review: Tastefull meal - worth a visit!!
Passage Text:
Best meal we’ve had in NYC! The pasta was just delicious / super fresh & the staff very friendly and kind. We would recommend it for sure!
Score: 0.8786392
---
ID: 22079
Doc Title: review_375834633
Restaurant Name: Orso
Title Review: Always a crowd pleaser!
Passage Text:
Love this restaurant and still mourn the closing of the LA spot. The best pastas and a perfect place to have lunch that "feels" like NYC! Very traditional and located very near the theater district, so you can hop in for an early dinner pre-show as well. You really can't go wrong ordering everything on the menu but my last visit, I had them make me a simple pasta with tomatoes and basil.
Score: 0.8776474
---
ID: 69039
Doc Title: review_467680511
Restaurant Name: Forlini_s_Restaurant
Title Review: The best. The very best.
Passage Text:
If tradition, quality service, and first-rate homemade pasta is your desire, then look no more. This place is simply the best in NYC. I've been here several times after stumbling on it last year. Wish I had found it earlier in my career; it would have made many of my previous visits to NYC even more satisfying to the palate -- and wallet. Love the family atmosphere.
Score: 0.8749021
笔者决定使用大规模分布式数据处理的保留手段, RabbitMQ + Celery + 多个 Celery worker 。 只需要简单编辑一下 docker-compose.yml ,新建 Celery worker 的代码 和 Dockerfile ,即可享受大规模分布式数据处理的乐趣。
实验结果和代码样例
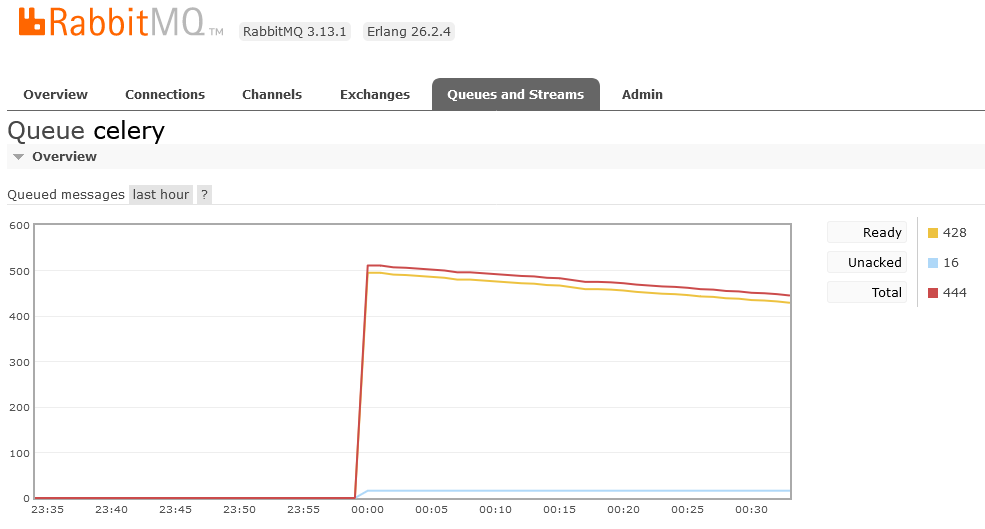
根据 RabbitMQ 控制台,我们在大概 30 分钟的时间里完成了 10% 的数据索引,那么索引整个 50 万条 review 大约需要 5 个小时左右。
这里的瓶颈是我们的 docker-compose 自动提供的 ES 集群是单线程的。 为了节约配置的时间,我们在最初进行原型开发的时候可以直接使用 Elastic Cloud 针对推理优化过的集群。
代码样例: Jupyter Notebook
这一代码样例实现了实验计划的全部功能(除 re-ranking 之外):
- 语义搜索:验证 Cohere 提供的 embedding 算法和 ElasticSearch 的 ANN 搜索。
- 建立 ES 的导入数据 Ingest Pipeline, chunking 长文到合适规模。
- 导入真实世界测试数据: TripAdvisor 上的 50 万条纽约市餐厅评论
下文预告
我们在本节中使用 ES 的 ingest pipeline 引入大规模数据,测试语义搜索功能。
下一节将测试 Cohere 提供的 re-ranking 算法,在前 100 条
纽约最好的意大利面饭馆
中,重新排序出第一二三四名来。
实验计划
- 小样本测试
- 语义搜索:验证 Cohere 提供的 embedding 算法和 ElasticSearch 的 ANN 搜索。
- 建立 ES 的导入数据 Ingest Pipeline, chunking 长文到合适规模。
- 重排序:验证 Cohere 提供的 re-ranking 算法
- 大样本测试:
- 构建本地测试环境
- 导入真实世界测试数据
本节完成了 2.2 。